Distributed systems have become increasingly prevalent in today’s technology landscape, enabling scalability, fault-tolerance, and high availability. However, designing and managing distributed systems come with their own set of challenges. One fundamental concept that plays a crucial role in distributed system design is the CAP theorem. In this blog we will I’ve deep into understanding the CAP theorem, its components, tradeoffs, and some real world examples
What is CAP theorem
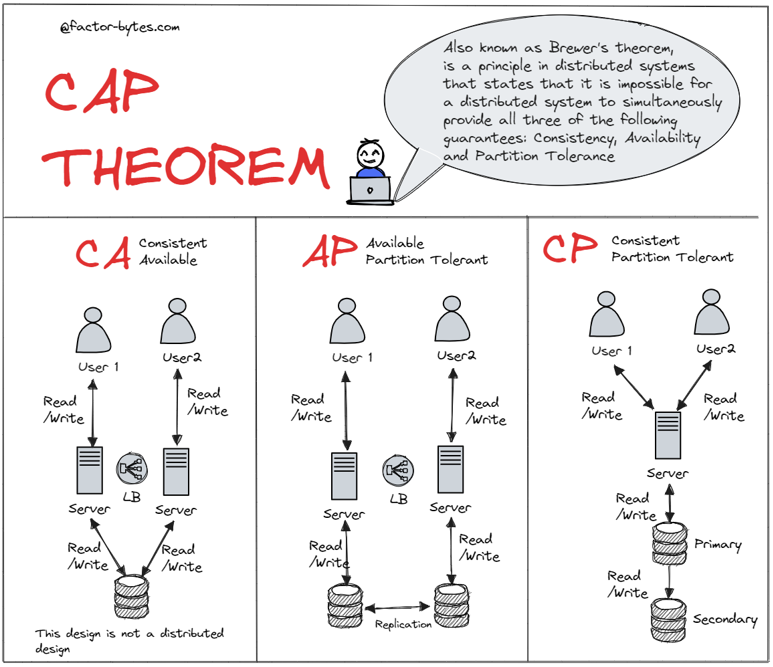
The CAP theorem, also known as Brewer’s theorem, was formulated by computer scientist Eric Brewer in the early 2000s. It states that it is impossible for a distributed system to simultaneously provide all three of the following guarantees: Consistency(C), Availability(A), and Partition Tolerance(P). The CAP theorem states that in the event of a network partition (P), a distributed system must choose between maintaining Consistency (C) or Availability (A). In other words, it is impossible to achieve both Consistency and Availability in the presence of network partitions.
Components of CAP theorem
- Consistency: Consistency in the context of the CAP theorem refers to the requirement that all nodes in a distributed system have the same data at the same time. It ensures that when a change is made to one node’s data, all other nodes eventually reflect that change. In a consistent system, data updates propagate to all nodes before allowing any subsequent read operations. This ensures that users always observe a coherent and up-to-date view of the system.
Achieving strong consistency can be challenging in distributed systems, especially in the presence of network delays, failures, or high latency. Coordinating updates across nodes to maintain consistency often introduces additional complexity and performance overhead.
- Availability: Availability refers to the property that every request made to the system receives a response, even in the face of failures or network partitions. An available system remains responsive to user requests and continues to operate even when individual nodes or components experience failures.
Ensuring high availability typically involves redundancy and fault-tolerance mechanisms, such as replication, load balancing, and failover strategies. These mechanisms allow the system to continue functioning by redirecting requests to healthy nodes or employing backup replicas of data.
- Partition Tolerance: Partition Tolerance represents a distributed system’s ability to continue operating despite network partitions or communication failures. Network partitions occur when nodes in a distributed system are unable to communicate with each other due to network issues or other factors. This can result in message loss, delays, or nodes being isolated from each other.
Partition tolerance is a fundamental requirement in distributed systems because complete network reliability cannot be guaranteed. With partition tolerance, a distributed system can continue to function and provide services even when some nodes are unable to communicate with each other.
The CAP theorem states that in the presence of network partitions (P), a distributed system must decide whether to preserve consistency (C) or availability (A). Achieving both strong consistency and high availability simultaneously during network partitions is impossible.
Understanding these three components of the CAP theorem is crucial for designing distributed systems that strike a balance between consistency, availability, and partition tolerance based on the specific requirements and trade-offs of the application or use case.
CAP theorem trade-offs
The CAP theorem has three system configurations: CP, AP, and CA.
- CP Systems (Consistency and Partition Tolerance):
CP systems prioritize Consistency and Partition Tolerance over Availability. In these systems, when a network partition occurs, they choose to maintain strong consistency even if it means sacrificing availability temporarily. This means that during a partition, updates to the system may be blocked until consistency is achieved or the partition is resolved.
CP systems are typically used in scenarios where data consistency is crucial, such as financial applications or systems that require strict synchronization. They are willing to sacrifice availability during network partitions to ensure that all nodes have the same consistent view of the data.
- AP Systems (Availability and Partition Tolerance):
AP systems prioritize Availability and Partition Tolerance over strong Consistency. These systems choose to remain available and provide responses to user requests even during network partitions, accepting that different nodes may have temporarily inconsistent views of the data.
AP systems are often used in scenarios where high availability is essential, such as real-time collaboration applications or content delivery networks (CDNs). They prioritize providing a responsive service even if it means accepting eventual consistency and allowing temporary inconsistencies across nodes.
- CA Systems (Consistency and Availability):
CA systems aim to achieve both Consistency and Availability, but they sacrifice Partition Tolerance. In other words, they prioritize maintaining a consistent view of the data and providing responses to user requests even when there are no network partitions.
CA systems are typically deployed in environments with strong network reliability and low chances of network partitions. They are well-suited for applications where data consistency and high availability are critical, such as traditional single-site databases.
It’s important to note that achieving all three properties simultaneously (Consistency, Availability, and Partition Tolerance) in a distributed system is impossible according to the CAP theorem. Therefore, system designers must make deliberate trade-offs based on their application’s requirements and priorities.
Real World Examples
- Social Media Platforms: Social media platforms, such as Facebook and Twitter, often prioritize Availability and Partition Tolerance (AP systems). These platforms aim to provide a seamless user experience, allowing users to post, share, and interact with content in real-time, even in the presence of network partitions. While consistency is desirable, social media platforms can tolerate temporary inconsistencies, such as delayed updates or discrepancies in user feeds, as long as the system remains highly available.
- Financial Systems: In financial systems, such as banking or stock trading applications, maintaining strong Consistency (CP systems) is of utmost importance. These systems require strict synchronization and ensure that all transactions are processed consistently across all nodes, even during network partitions. Ensuring data consistency is critical to prevent any discrepancies or inconsistencies in financial transactions that could have severe consequences.
- E-commerce Platforms: E-commerce platforms, like Amazon or eBay, often employ a blend of Consistency and Availability (CA systems). These platforms aim to provide a consistent view of product catalogs, prices, and inventory across all nodes while ensuring that the system remains highly available. Temporary unavailability during network partitions may be acceptable, but maintaining data consistency across the platform is crucial for accurate product information and order processing.
- IoT Systems: Internet of Things (IoT) systems, where numerous devices communicate and exchange data, often prioritize Availability and Partition Tolerance (AP systems). IoT systems deal with large volumes of data generated by devices in real-time. Prioritizing availability allows the system to handle device failures or network disruptions without affecting the overall operation. In certain cases, IoT systems may choose eventual consistency to handle data synchronization and handle network partitions.
- Content Delivery Networks (CDNs): CDNs focus on providing efficient content delivery and prioritize Availability and Partition Tolerance (AP systems). CDNs replicate and distribute content across multiple nodes globally to reduce latency and improve user experience. While consistency is desirable, CDN systems can tolerate temporary inconsistencies across nodes, ensuring that users can access content quickly and reliably.
Handling Tradeoffs
As discussed above, CAP theorem brings tradeoffs, however, there are strategies that can be employed to handle the trade-offs imposed by the CAP theorem.
- Eventual Consistency: Eventual consistency is a popular approach used in distributed systems to achieve a balance between Availability and Consistency. Rather than enforcing immediate consistency across all nodes, eventual consistency allows for temporary inconsistencies that eventually converge to a consistent state over time. This approach allows for high availability and responsiveness while still providing eventual data convergence.
- Quorum Systems: Quorum systems involve dividing the distributed system into groups or partitions and defining a threshold of nodes that need to agree on a decision or operation. Quorum systems provide a way to balance Consistency and Availability. By requiring a subset of nodes to reach a quorum before performing certain operations, it ensures that decisions are made based on the agreement of a sufficient number of nodes while allowing for availability even during network partitions.
- Consensus Algorithms: Consensus algorithms, such as the Paxos algorithm or the Raft algorithm, provide a means for achieving Consistency in distributed systems. These algorithms ensure that nodes agree on a specific order of operations or decisions, even in the presence of failures or network partitions. Consensus algorithms enable systems to maintain strong consistency while still offering fault tolerance and availability.
- Multi-Datacenter Replication: In scenarios where high availability is crucial, multi-datacenter replication can be employed. By replicating data across multiple geographically distributed datacenters, systems can ensure that data remains available even if one datacenter experiences a failure or network partition. Replication strategies, such as active-active or active-passive replication, can be used to balance availability and consistency based on the specific requirements of the application.
- Hybrid Architectures: In some cases, a combination of different approaches and trade-offs may be employed in a hybrid architecture. Different parts of a distributed system may have varying requirements, allowing for different levels of consistency, availability, and partition tolerance. By carefully segmenting the system and applying different strategies to each segment, system designers can achieve an optimal balance between the desired properties.
It’s important to note that these strategies are not exhaustive, and the choice of strategy depends on the specific requirements, constraints, and priorities of the distributed system. Each strategy comes with its own advantages and trade-offs, and system designers need to carefully evaluate and select the appropriate strategy based on their application’s needs.
While the CAP theorem is still relevant, it’s worth noting that there have been some discussions and debates around it in recent years. Some argue that the theorem’s assumptions are too strict or don’t fully reflect the complexities of real-world distributed systems. Consequently, alternative models, such as the PACELC theorem and the CAP twelve years later paper, have been proposed to provide a more nuanced perspective.
Overall, the CAP theorem remains a valuable conceptual framework for understanding the challenges and design decisions involved in distributed systems, although it may not capture every aspect of every real-world scenario.
